
*This website contains affiliate links. If you click on these and make a purchase, we will receive a small percentage of the sale.
Scraping e-commerce websites usually involve crawling the whole domain with a standard crawling framework or developing a dedicated crawler or scraper. Both of these options are time-consuming and resource-intensive. This is what Beagle Scraper plans to solve by developing and becoming an important e-commerce scraper, open-source and readily available for anybody looking to start collecting data right away.
This tutorial has three parts:
- PART 1: How to use the scraper
- PART 2: How to modify the scraper
- PART 3: How to create a custom scraper function
What is Beagle Scraper? How will it solve the issue?
Beagle Scraper is a category scraper for e-commerce websites. The main goal is to develop a plug-and-play solution for developers and marketers looking to start collecting data right away, without spending too much time coding or testing a scraper.
TL:DR paste any number of product page categories into a text file and run Beagle Scraper. It will access each page and collect data on all products listed in that category.
PART 1: Beagle Scraper Tutorial: How to use the scraper
Features
The main advantage of Beagle Scraper is that it will access and scrape only category pages. The hypothesis is that on category pages, all the relevant data for each product, like its name, image, price and rating are available in the listing. Thus, there is no need to access each product page individually.
A few advantages of scraping e-commerce data straight of category pages:
- Fast deployment: it can collect data on hundreds of products (items) from just a few pages
- Fewer resources used: unlike crawlers, it will not scrape a whole domain, thus by limiting the number of pages scraped, Beagle Scraper limits the number of requests and minimizes the time spent collecting data.
- Extracts only the required data: it avoids spending time and resources on pages where the data is not present.
How to install Beagle Scraper
Beagle Scraper is developed with Python 2.7 and BeautifulSoup4 and requires both Python and BS4 to run.
To install BeautifulSoup4, you will need to run this command.
$ pip install beautifulsoup4
Also, tldextract and selenium need installed through the following commands:
$ sudo pip install tldextract $ pip install selenium
Once you have both libraries installed on your machine, you can simply download the Beagle Scraper source code from GitHub.
Beagle Scraper Usage
Beagle Scraper is an easy to use e-commerce scraper. These are the steps you need to do to start scraping:
- Create a file urls.txt (in the same folder with the source code) and paste product category pages. Insert each URL on a new line
https://www.amazon.com/TVs-HDTVs-Audio-Video/b/ref=tv_nav_tvs?ie=UTF8&node=172659&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=WQG6T4RDNW1YMS15T8Q8&pf_rd_r=WQG6T4RDNW1YMS15T8Q8&pf_rd_t=101&pf_rd_p=2905dcbf-1f2a-4de6-9aa1-c71f689a0780&pf_rd_p=2905dcbf-1f2a-4de6-9aa1-c71f689a0780&pf_rd_i=1266092011
https://www.bestbuy.com/site/tvs/4k-ultra-hd-tvs/pcmcat333800050003.c?id=pcmcat333800050003
Note: Because Beagle Scraper is a product category scraper, you can only provide category pages. Once you feed into the scraper a category page, it will start gathering data, change pages and scrape all the products in that category.
2. Run in a terminal the file start_scraper.py
$ python start_scraper.py

3. Get the scraped data from the freshly created folder with the name job_dd_mmm_yyyy (output is a JSON file composed of list of products)
[{
"url": "https://www.amazon.com/TCL-55S405-55-Inch-Ultra-Smart/dp/B01MTGM5I9/ref=lp_172659_1_1/136-0781164-7684209?s=tv&ie=UTF8&qid=1523933747&sr=1-1",
"rating": "4.3 out of 5 stars",
"price": "399",
"domain": "amazon.com",
"title": "TCL 55S405 55-Inch 4K Ultra HD Roku Smart LED TV (2017 Model)"
},
{
"url": "https://www.amazon.com/TCL-32S305-32-Inch-Smart-Model/dp/B01MU1GBLL/ref=lp_172659_1_2/136-0781164-7684209?s=tv&ie=UTF8&qid=1523933747&sr=1-2",
"rating": "4.2 out of 5 stars",
"price": "159",
"domain": "amazon.com",
"title": "TCL 32S305 32-Inch 720p Roku Smart LED TV (2017 Model)"
}]
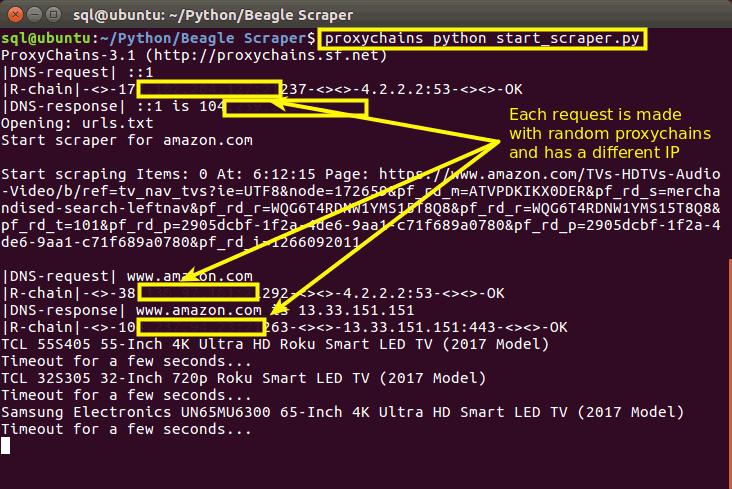
Optional – use proxychains and proxies to spread your requests over multiple IPs
Here is a short tutorial on how to setup proxychains and use it with a Python script.
As there is no login required, if you want to get private proxies for Beagle Proxies, I advise looking into SEO proxies, they are usually cheaper proxies, but they will do the job for scraping data of e-commerce websites.
TL:DR: After setting up proxychains and inserting your proxy details, run the command:
$ proxychains python start_scraper.py
How to Contribute
Your help in creating the largest open source e-commerce scraper is welcomed. Beagle Scraper requires a custom function for each e-commerce website.
Read the next part if you want to customize Beagle Scraper for any e-commerce website you need or if you want to contribute.
PART 2: Beagle Scraper Tutorial: How to modify the scraper
If you plan on using Beagle Scraper for another e-commerce website, or for browsing a product category list, you need to understand how Beagle Scraper gets its data and how you could modify the code. You only need to know how amazon_scraper() function receives the data. Once you understand this part, with some basic HTML knowledge, you can develop your scraper function for other e-commerce websites.
How amazon_scraper() gets data from Amazon.com
Beagle Scraper does the simple job of getting each product HTML code from the listing. By using the Inspector in your browser, visualize what data to extract.

By navigating to the category page and inspecting the listing, we can see that each product is contained within the div with class “s-item-container”. Check the Beagle Scraper code, you can see that this the function to extract all similar divs from the scraped page.
Following, all the scraped product divs are stored as a list of objects in a variable called items_div. Here’s the actual code to find all divs and save them into the items_div variable.
#store all product divs from the page in a list
items_div = shop_soup.find_all('div', {'class': 's-item-container'})
If you need to change the store and scrape another website, this is the piece of code that you will need to change. You will need to adjust it to that website’s HTML class or id that contains the product details.
How product details are extracted
After all product data from the category page is obtained, the next task for Beagle Scraper is to loop through the items_div list and select each product.
The logic behind Beagle Scraper is simple: once a product div is selected, it looks for selected data to see if it exists and extracts it.
The data Beagle Scraper is looking for:
- Product title
- Product rating
- Price
- URL to the product link page
The code to extract each product’s details is this one (Note that if statements are used only to verify if the product details are present – the logic is simple: if the element exists, save it: if it doesn’t exist, skip and move to next detail):
#loop the scraped products list and extract the required data
for div in items_div:
try:
#check if current page is the first category page
if div.find('span', {'class': 'sx-price-whole'}):
price = str(div.find('span', {'class': 'sx-price-whole'}).text.strip())
else:
price = str(div.find('span', {'class': 'a-size-base a-color-base'}).text.strip())
#verify if the product is rated
if div.find('span', {'class': 'a-icon-alt'}):
rating = str(div.find('span', {'class': 'a-icon-alt'}).text.strip())
else:
rating = 'Not rated yet'
#append data in list of items
amazon_products_list.append({
'title' : div.find('a', {'class': 'a-link-normal s-access-detail-page s-color-twister-title-link a-text-normal'})['title'],
'url' : div.find('a', {'class': 'a-link-normal s-access-detail-page s-color-twister-title-link a-text-normal'})['href'],
'price' : str(price),
'rating' : str(rating),
'domain' : domain_name})
print div.find('a', {'class': 'a-link-normal s-access-detail-page s-color-twister-title-link a-text-normal'})['title']
except:
pass
#random time delay 1 to several seconds (change 6 with the max seconds for delay)
time_out(6)
#END DATA EXTRACTION
Change page to extract all category products
Almost all categories on an e-commerce website have products spanning several pages. Once Beagle Scraper extracts all product details from a page, the “change page” logic will start looking for the pagination HTML details.
Here, Beagle Scraper does another simple and straightforward task of checking to see if the pagination details for the next page exist. If it exists, it will output the scraped data, call a timeout to throttle the requests performed for this domain, change the page URL and call the scraper function – amazon_scraper() – again on the new page. However, if the current scraped page is the last one, Beagle Scraper will output the scraped data and terminate the scraping.
#PAGINATION AND CHANGING THE NEXT PAGE
#check if current page is last for last page by reading the page button link
if shop_soup.find('a', {'id': 'pagnNextLink'}):
#loads next page button link
next_page_button = shop_soup.find('a', {'id': 'pagnNextLink'})['href']
next_page_button_href = 'https://www.amazon.com' + str(next_page_button)
#write scraped data to json file
output_file(file_name, amazon_products_list)
#change 5 to max seconds to pause before changing to next page
pagination_timeout(5)
amazon_scraper(next_page_button_href)
else:
#write scraped data to json file
output_file(file_name, amazon_products_list)
print 'Category Scraped Completed '+'Items: '+str(len(amazon_products_list))+' At: '+str(now.hour)+':'+str(now.minute)+':'+str(now.second)
#END PAGINATION
How the output is performed
I should mention a few things on how and when the scraped data is outputted. The function of outputting data is called output_file().
The output_file() function saves data as a list of dictionaries into JSON format whenever one of these situations occur:
- Beagle Scraper finishes scraping a URL (and changes the page)
- A pagination issue occurs – when a URL is fed twice into Beagle Scraper (in this situation will check for the URL in the log.csv scraped log and skip scraping it the second time – but it will try to output data, even if there is nothing to output) – this is more of a cautionary save, just to make sure no scraped data is lost.
Output data is saved into a folder (created with the first saved data inside the folder where the source code is located) with the name job_[dd_mmm_yy] to easily track the scraped data over several periods of time.
The output is in JSON format and can easily be accessed by any JSON reading function, (even written in another language – a necessary mention for those that just started coding), or manually with a text editor.
A few words on Beagle Scraper middlewares.py functions
The middleware functions are created to facilitate the scraper. These are helper functions and here are a few of them
- scrape_log(open_link) – it takes the current parsed URL as variable, logs into a csv file all the URLs scraped. In case your scraper stopped or your machine powers off, you can check in the log_[scrape_date].csv the last scraped URL. And you can resume Beagle Scraper from this URL.
- error_log(URL, error_message) – it takes the current parsed URL (URL )and a string for(error message) as variable. If you want to insert this function anywhere in the code, replace URL with the page_link (the current parsed URL) and pass a string for error_message – the string is used for logging the issue. For example, for pagination issues, this function is used as:
- error_log(page_link, ‘Pagination issues’)
- output_file(domain, products_list) – This is a self-explanatory function, it gets the domain of the currently scraped URL and the scraped data product_list list variable. It dumps the list of scraped items into a JSON file.
- time_out(seconds) and pagination_timeout(seconds) – These functions are used to limit the number of requests. Their main purpose is to avoid blocks or IP bans due to the high number of requests. By default, these two functions have a low limit of 2 seconds. And the high limit is variable – which you can set to any number of seconds higher than 2. They will stop the scraper for a random number of seconds (between 2 and n number of seconds). For example, pagination_timeout(5), when changing the page, before starting to scrape the new page, will pause the scraper for a random number of seconds between 2 (minimum seconds) and 5 (the number of seconds you passed to the function).
What is start_scraper.py
This file is used to open the urls.txt file and start Beagle Scraper and this is the sequence:
- Opens the urls.txt file
- Extract each URL (from each link)
- Checks if for the URL’s domain is a scraper function in beagle_scraper.py
- If there is a function, it will call the function
- When the URL is parsed and product data scraped, it logs the URL
- Checks the next URL from urls.txt and repeats the process
PART 3: Beagle Scraper Tutorial: How to create a custom scraper function
This is the fun part. If you want to create a custom scraper function for an e-commerce website that is not supported yet by Beagle Scraper or if you want to contribute to the project, here’s what you need to do:
- Choose the website
- Identify the HTML wrapper tags and CSS class (or id) for product listing
- Add the pagination logic
- Customize the start_scraper.py to identify the domain and start the scraper
All these steps are easy to follow, so you can create a custom function in Beagle Scraper within minutes and start scraping. As I previously mentioned, the goal of Beagle Scraper is to become an e-commerce scraper easy to use by programmers and marketers alike. Let’s start!
Choose the website
First, before considering developing a custom function, I recommend you check if the website you want to scrape has an API that you can use and access. If the API exists, consider using it. However, you should consider creating a scraper function if the API:
- Limits the number of requests
- You can’t access it
- The API implementation requires a lot of effort and is time-consuming
In this tutorial, I chose homedepot.com for building the custom scraper function called homedepot_scraper(). While they have an API, this API is “unofficial” and there is no clear documentation on their API and its use cases. So, let’s create a scraper function for homedepot.com
Before you start building the scraper function, you need a category URL around which to develop the homedepot_scraper(). Consider the following category page:
https://www.homedepot.com/b/Electrical-Home-Electronics-AV-Accessories/N-5yc1vZc64j
Create a product list
After deciding for what website to create the scraper, you need to do three things:
- Create a new empty product list at the top of beagle_scraper.py under the format [website]_products_list
- Define the scraper function
- Copy the code from another scraper function (for example from amazon_scraper() function) within the new scraper function (in this case homedepot_scraper()) and replace the product list amazon_products_list with homedepot_products_list
Here’s the first part of the homedepot_scraper, the part that opens the URL and starts the scraper
def homedepot_scraper(category_url):
#assign the function's parameter to a variable
page_link = str(category_url)
now=datetime.now()
print ''
#To avoid pages with pagination issues, check if the page wasn't scraped already
if page_link not in scrape_page_log:
#appends to log the url of the scraped page
scrape_page_log.append(page_link)
print 'Start scraping '+'Items: '+str(len(homedepot_products_list))+' At: '+str(now.hour)+':'+str(now.minute)+':'+str(now.second)+' Page: '+str(page_link)
#open url
shop_page_req_head = urllib2.Request(page_link)
shop_page_req_head.add_header('User-Agent', 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0')
#load page and create soup
shop_page = urllib2.urlopen(shop_page_req_head)
shop_soup = BeautifulSoup(shop_page, 'html.parser')
#get the domain of the url for exporting file name
domain_url = tldextract.extract(page_link)
#join to add also domain suffix link domain.com
domain_name = '.'.join(domain_url[1:])
file_name = domain_url.domain
Extract product details (#DATA EXTRACTION)
Now the next step is to get the HTML tags and CSS classes and id for data that will be extracted. With the Inspect Element from your browser, you need to get the HTML and CSS wrapping the product details. In the HomeDepot case, each product is contained within this div.
<div class="pod-inner">
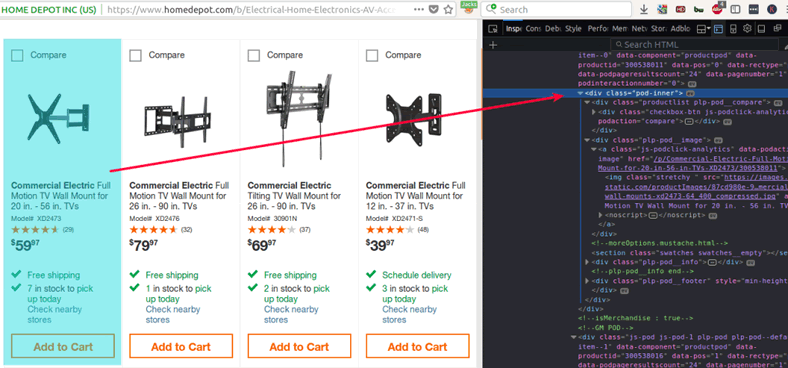
And within this div, the product details that we need to extract are:
- Product title
- Product page URL
- Product Price
Once we get these details, the next step is to insert them in the data extraction part of the homedepot_scraper() with the custom BeautifulSoup4 format. You need to insert these details within the loop that iterates through the <div class=”pod-inner”> items.
#DATA EXTRACTION
#store all product divs from the page in a list
items_div = shop_soup.find_all('div', {'class': 'pod-inner'})
#loop the scraped products list (items_div) and extract the required data
for div in items_div:
try:
#append data in list of items
homedepot_products_list.append({
'title' : div.find('div', {'class': 'pod-plp__description js-podclick-analytics'}).text.strip(),
'url' : 'https://www.homedepot.com'+str(div.find('a', {'class': 'js-podclick-analytics'})['href']),
'price' : div.find('div', {'class': 'price'}).text.strip()[1:-2],
'domain' : domain_name})
print div.find('div', {'class': 'pod-plp__description js-podclick-analytics'}).text.strip()
except:
pass
#random time delay 1 to several seconds (change 6 with the max seconds for delay)
time_out(6)
#END DATA EXTRACTION
now=datetime.now()
print 'Page completed '+'Items: '+str(len(homedepot_products_list))+' At: '+str(now.hour)+':'+str(now.minute)+':'+str(now.second)
Let’s change the page (#PAGINATION setup)
The final part of constructing a custom scraper function is to make the scraper identify if there are other pages with products within this category. The logic behind the pagination setup is the following:
- Identify if there is a next page button (or URL) within the pagination setup
- Output current page extracted data to file
- Call the scraper on the “next page” URL and restart the process
Now we need to setup the scraper function to identify if there is a next page button and insert it into the BeautifulSoup format.

Because we use the find_all() BS4 function, Beagle Scraper will extract all URLs from the pagination setup. Thus, we need to instruct the scraper to choose for the Next page only the last URL from all extracted URLs. As you can see, these are all the urls the find_all() function obtained from the pagination. But we are only interested in the next page URL, which is actually the last item of this list and hast the title=”Next”. Now we need to instruct Beagle Scraper that while the last URL on the pagination list has the title “Next”, it should consider this <a> tag’s href as the next page to scrape and self-call homedepot_scraper() on this URL.
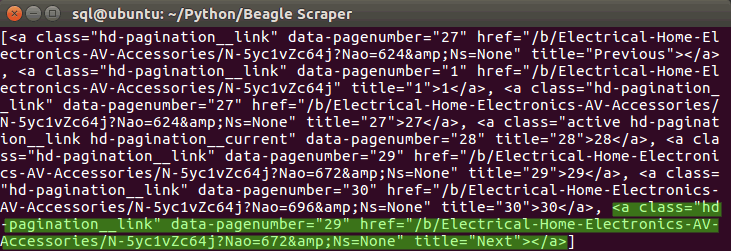
Assign a variable for the next page URL and within the HTML tag for Next page button, you need to extract the URLs. In the homedepot case, the URL doesn’t have the root domain, so you will need to prepend in as a string.
#PAGINATION
#check if current page is last for last page by reading the page button link
if shop_soup.find('li', {'class': 'hd-pagination__item hd-pagination__button'}):
#loads next page button link
next_page_click = shop_soup.find_all('a', {'class': 'hd-pagination__link'})
#Get the last url from the find_all extracted list and while has the title "Next" run the scraper
while next_page_click[-1]['title'] == 'Next':
#append the root domain as string (because homedepot's internal url's don't have root domain)
next_page_button_href = 'https://www.homedepot.com'+str(next_page_click[-1]['href'])
try:
#write scraped data to json file
output_file(file_name, homedepot_products_list)
#change 5 to max seconds to pause before changing to next page
pagination_timeout(5)
homedepot_scraper(next_page_button_href)
break
except:
break
else:
#write scraped data to json file
output_file(file_name, homedepot_products_list)
print 'Category Scraped Completed '+'Items: '+str(len(homedepot_products_list))+' At: '+str(now.hour)+':'+str(now.minute)+':'+str(now.second)
#END PAGINATION
And… you’re done! This is all you need to do for creating a new Beagle Scraper function. The last step is to modify the start_scraper.py file to recognize the domain homedepot.com and call the homedepot_scraper().
Modify the start_scraper.py file to add homedepot.com
A little backdrop on how Beagle Scraper works.
- You insert all product category URLs within the urls.txt file
- Then you run the start_scraper.py file that opens and loops through urls.txt file content
- start_scraper.py identifies the domain of the URLs and calls the beagle_scraper.py custom scraper function
Now we need to create the logic for third steps for the homedepot.com URLs by appending the code to identify the domain and call the homedepot_scraper. This is done through with the following logic:
#start_scraper.py
#identify the domain of the url from urls.txt
if domain_ext == 'homedepot.com':
try:
#calls the homedepot_scraper from beagle_scraper.py
scrape.homedepot_scraper(category_url)
pass
except:
pass
Start scraping!
Well done! You have created your custom function for Beagle Scraper. All you have to do now is to start scraping some data.
To wrap up
I think this is all there is to know about Beagle Scraper. With the above information at hand, you can modify the scraper of simply develop it by creating custom scraper functions for other e-commerce websites.



